Finance & Business
You Don’t Have a Pricing Problem. You Have a Cost Visibility Problem.

Published date: 11/05/2026

Most SaaS pricing debates start in the wrong place.
Teams argue about tiers. They agonize over seat counts versus usage limits. They benchmark competitors. They run surveys asking customers what they’d pay. Then they launch, watch margins compress, and wonder what happened.
Here’s what happened: the pricing model was built on cost estimates, not cost reality. And estimates age badly.The dirty secret of SaaS unit economics
When a VP of Product or a pricing consultant builds a model for a new plan, they’re working backward from assumptions. Infrastructure costs are approximated. Shared resource consumption is averaged. AI usage is guessed. Customer variance is smoothed into a single line.
The model says a customer on the Growth plan should cost $80/month to serve. The actual cost, once you trace it back through the real infrastructure, is closer to $190 for your heaviest accounts and $12 for your lightest. The average looks fine. The tail is quietly killing you.
This is not a pricing strategy problem. It’s a data problem. Specifically, it’s a missing dataset problem.
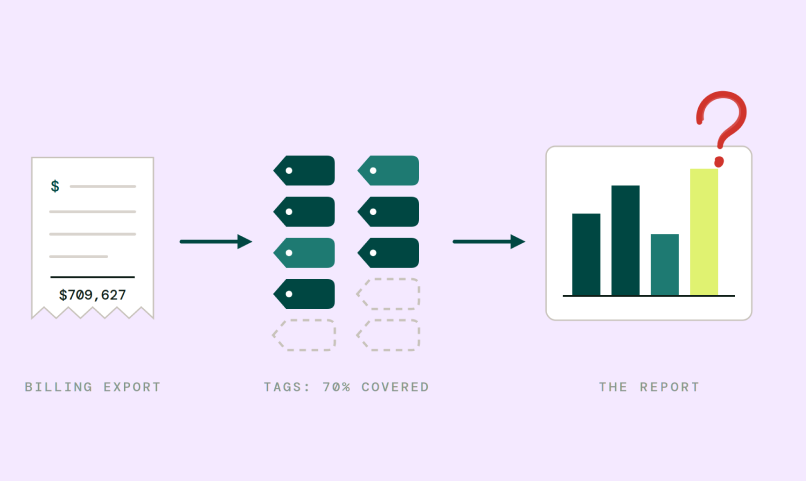
Traditional cloud cost tools were built for FinOps teams managing infrastructure budgets. They read billing exports, parse CloudTrail logs, and organize spend by account, region, or tag. That’s useful for the engineering team trying to right-size EC2 instances.
It’s not useful for pricing.
Pricing teams need cost organized differently, by customer, by product line, by feature, by the usage unit they actually charge for. A billing export doesn’t know which customer triggered which workload. It doesn’t know that one enterprise account runs scan jobs that consume 40x more compute than anyone on the same plan. It doesn’t know that your AI feature costs three times more for power users than casual ones.
The billing layer doesn’t have this context. It never did. It was built to tell cloud providers how much to charge you, not to tell you how much it costs to run each customer’s workload.
To answer that question, you need a different data source entirely.
When you instrument your infrastructure based on runtime data, reading actual traffic, actual service calls, actual resource consumption as it happens, the cost picture looks very different.
You can see which customers are driving which workloads. You can trace a database query back to the feature that triggered it, and from there to the customer who used it. You can watch shared resources like Kafka or Elasticsearch and understand which tenants are consuming how much, without requiring engineers to tag anything.
This is not a theoretical capability. It exists now, deployed in production for companies doing exactly this analysis.
What do they find?
Most find that their mental model of cost distribution is wrong. The spread between lightest and heaviest consumers is wider than expected. A small percentage of accounts, usually enterprise, usually in the middle of your plan stack, are consuming at a rate that makes their ARR look like a discount.
One company found 360 accounts where cost-to-serve exceeded revenue. Total exposure: $1.3M in annual losses, invisible until runtime attribution mapped cost back to customers. The losses weren’t in unprofitable accounts that anyone expected to be unprofitable. They were hiding in plans that looked like healthy ARR.
This kind of margin compression is getting worse, not better.
AI features change the cost structure of a SaaS product in ways that seat-based or even usage-based pricing often doesn’t capture. An AI agent that runs a multi-step workflow doesn’t consume a fixed amount of compute. It consumes based on complexity, on input size, on how many tools it calls, on how many tokens it burns along the way. Two customers using the same AI feature can have 10x different cost profiles.
If your pricing model treats them the same, one of them is underwriting the other.
The companies that are going to get AI pricing right are the ones that can see token consumption, agent actions, and tool call volume at the customer level, and build pricing that maps to that reality. Not per-seat. Not per-thousand-requests. Pricing structures that reflect the actual cost drivers in the product.
That requires runtime data. There’s no other way to get it at this level of granularity.
You can identify which segments are margin-negative before they show up in a board presentation. You can see which plan tiers have the widest cost variance and design usage limits or add-ons that map to actual consumption. You can test the margin impact of a new capability before you price and ship it, using real baseline data rather than modeled assumptions.
You can also build pricing models that were never possible before. Consumption-based pricing stops being a gamble when you know exactly how much each unit of consumption costs to deliver. Value-based pricing becomes defensible when you can show what you actually spend to generate the outcome you’re charging for.
The agentic era makes this more urgent. If you charge $250 per completed task, you need to know whether that task cost $80 or $380 to run. The answer changes everything: which workflows to price higher, which to redesign, which customers are profitable at your current rate. Without runtime data, you’re flying blind on your most important pricing decisions.
You can answer the question pricing teams have always needed to answer but rarely could: what does it actually cost to deliver this value to this customer?
When you have that answer, pricing strategy stops being guesswork. It becomes a business advantage.
Before debating packaging tiers or feature gating, ask one prior question: do we actually know what it costs to serve each customer, each plan, each feature?
If the answer involves spreadsheets and estimates, the pricing model is sitting on a foundation that won’t hold as the product scales.
Start with cost reality. Everything else follows.
Attribute maps cloud and AI infrastructure cost to customers, products, and features using runtime data, without tagging. See how it works for pricing teams.