Engineering Finance & Business
Cloud cost questions tend to sound simple.
- What does this customer cost us?
- How expensive is this feature to run?
- Which teams or products are driving spend?
At a small scale, these are easy to answer with rough estimates. As systems grow, they quietly become some of the hardest questions in the organization.
Not because teams lack data, but because the way modern infrastructure works has changed.
Cost stopped mapping cleanly to ownership
In early-stage environments, cost usually aligns with ownership. A service belongs to a team. A database supports a product. An environment maps to a function.
As infrastructure scales, that mental model breaks.
Today’s systems are:
- Highly shared across teams and products
- Built on platform layers that serve many consumers
- Increasingly multi-tenant by design
Cost no longer belongs to one owner. It’s distributed across usage patterns. At that point, asking “who owns this?” stops being the right question.
Shared infrastructure hides real consumption
Most meaningful cloud costs live in shared layers:
- Data pipelines
- Streaming platforms
- Databases
- Networking and inter-service traffic
- Platform services supporting many workloads
These components rarely map one-to-one to a team, feature, or customer.
Instead, they absorb usage from across the organization, often unevenly. Some teams consume far more than others, but that imbalance is hard to see.
The result is cost opacity, even when overall spend is visible.
Why unit economics get blurry at scale
When cost can’t be tied directly to usage, unit economics suffer.
Teams struggle to:
- Explain margins by customer or product
- Understand which features are profitable
- Forecast spend accurately
- Make confident architecture or pricing decisions
Finance sees numbers that don’t reconcile. Engineering sees complexity that isn’t reflected in reports.
Everyone feels the gap.
The real issue is attribution, not visibility
The real issue isn’t visibility. It’s the model.
All organizations can see their cloud bill.
What breaks is the mapping between cloud resources and the business questions you’re being asked.
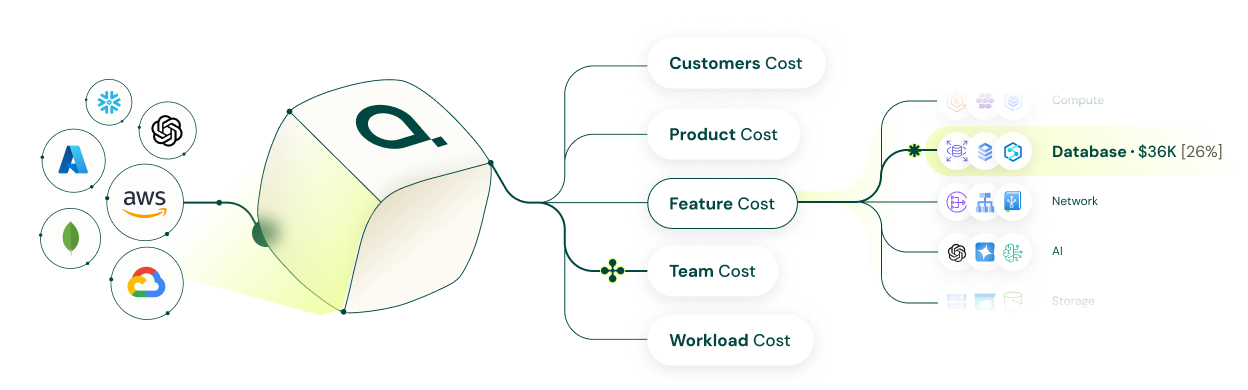
Cloud tags are useful for simple ownership. But unit-level questions are rarely one-to-one:
- A customer uses many services.
- A service serves many customers.
- A platform team supports many products.
- Shared infrastructure and network traffic don’t “belong” to a single owner.
Even with great tagging hygiene, tags can’t express that many-to-many reality or the allocation logic required to answer questions like “cost per customer,” “cost per feature,” or “which team is subsidizing which.”
That’s why unit economics get blurry at scale: the data exists, but the cost model doesn’t match how the system is actually consumed. It’s why our “FinOps without tagging” is so different.
How leading teams approach this differently
Teams that operate at scale are starting to rethink how cost is modeled:
- From bottom-up usage rather than top-down ownership
- From shared systems rather than isolated resources
- From actual consumption instead of assumptions
This shift makes unit-level cost explainable again, even in complex environments.
You can see how this works in practice in this case study on how Akamai explains unit-level cost across shared infrastructure without relying on tagging:
Or, if you want to see how this applies to your environment, you can schedule a demo here