Uncategorized
For 15 years, the entire FinOps industry has worked from the same data: billing exports, cloud tags, and month-end reports. That model worked when infrastructure was simple. It doesn’t work for teams running Kubernetes, shared services, and multi-tenant workloads at scale.
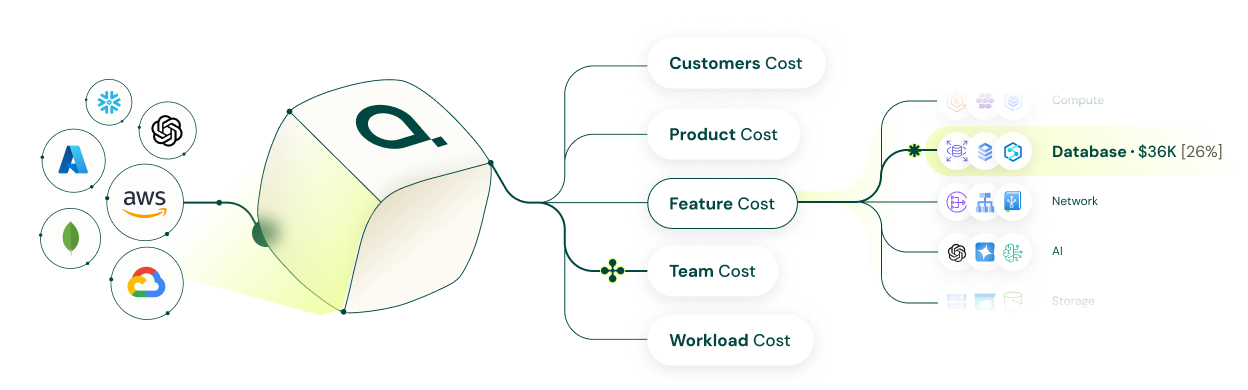
The problem isn’t cloud spend. It’s that most tools can’t explain it at the level that matters, by customer, by tenant, by feature, in time to act. That’s the gap Attribute was built to close.
Why cloud cost optimization breaks in Kubernetes and multi-tenant SaaS
Kubernetes hides the relationship between infrastructure and business value. One node group supports dozens of services. One Kafka cluster powers multiple features. Shared databases, queues, and search clusters don’t map cleanly to namespaces or tags.
Billing data tells you what you spent. It can’t tell you who drove it.
This creates predictable problems:
- No reliable cost visibility across shared clusters
- No customer or tenant-level unit economics
- Months spent on tagging hygiene with limited results
- No cost-to-serve data for pricing AI features or usage-based tiers
- No way to identify which customers have negative gross margin
These aren’t edge cases. They’re standard operating conditions for modern SaaS infrastructure.
Why billing-based FinOps tools fall short
Most FinOps tools start with the cloud bill. They ingest AWS CUR, billing exports, and resource metadata, then try to map spend back to teams through tags and allocation rules. That works when infrastructure is neatly structured. Most real environments aren’t.
A billing-only model has hard limits:
- It depends on tagging that rarely scales
- It arrives too late for real-time cost monitoring
- It can’t see inside self-managed infrastructure on EC2
- It guesses at shared cost allocation instead of measuring it
- It can’t connect cloud spend to customer profitability
The problem isn’t teams don’t understand FinOps. The source data is incomplete.
Runtime data is what Kubernetes cost attribution actually needs
Attribute takes a different approach. Instead of reading only billing data, it deploys a lightweight eBPF sensor that reads the live system, capturing runtime behavior, automatically discovering workloads and dependencies, and attributing cost based on what’s actually happening.
No other FinOps tool does this.
That gives teams:
- Real-time Kubernetes cost visibility without tagging
- Shared cost allocation based on actual consumption, not flat percentages
- Customer, tenant, feature, and team-level cost-to-serve
- Anomaly detection before month-end billing review
- Visibility into self-managed Kafka, Elasticsearch, and RabbitMQ that billing tools can’t see
The shift in question is simple: from “What did we spend?” to “Who consumed it, why, and did it generate margin?”
Kubernetes cost visibility without tagging
Tags are the industry’s standard attribution mechanism. They’re also expensive to maintain, impossible to enforce in dynamic environments, and useless for shared or self-managed infrastructure.
Attribute doesn’t need them. Because cost attribution starts from runtime behavior, not resource metadata, it works in environments where tags are missing, inconsistent, or structurally impossible. Teams can start with live workload discovery on day one instead of a months-long tagging project.
How to split Kubernetes costs by service, team, or tenant
When workloads share nodes, network paths, and infrastructure dependencies, splitting costs requires observing runtime consumption, not guessing.
Attribute tracks workload behavior in real time and allocates cost across services, engineering teams, tenants, and individual customers based on what each actually used. That produces defensible showback and chargeback, cleaner unit economics, and better planning data.
Shared cost allocation most tools get wrong
NAT gateways, data transfer, Kafka clusters, Elasticsearch, RabbitMQ, RDS, these resources support many workloads at once. If your tool only sees the final bill, it has to assume how to split those costs.
Attribute uses runtime observability to measure how workloads interact with shared infrastructure and assign cost accordingly. If multiple services use the same Kafka cluster, billing data can’t tell you which one drove the cost. Runtime behavior can.
Self-managed infrastructure visibility most tools miss
Cloud cost platforms generally handle managed services reasonably well. Visibility drops when teams run self-managed Kafka, Elasticsearch, or RabbitMQ on EC2. These become cost black boxes, often a significant share of total infrastructure spend, that no billing-based tool can see inside.
Attribute’s eBPF sensor operates at the kernel level, which means it can see into those systems. That closes one of the biggest blind spots in cloud cost optimization for SaaS companies with custom or performance-sensitive architectures.
How to track tenant-level cloud costs in a multi-tenant SaaS platform
One customer may consume far more compute, storage, or AI inference than another while paying the same contract price. Billing reports weren’t designed to surface that.
To track tenant-level cloud costs accurately, you need to connect runtime usage to the customer generating the load. Attribute does this across Kubernetes-based SaaS environments, making it possible to calculate cost per customer, compare revenue to infrastructure usage, and identify accounts with negative gross margin.
One Attribute customer found 360+ accounts where COGS exceeded revenue, representing $1.3M in losses they had no visibility into. That kind of data changes pricing, packaging, and customer success decisions.
Real-time cost visibility instead of waiting for billing data
Billing exports are useful for accounting. They’re not fast enough for operational decisions.
If a deployment causes excessive cross-zone traffic, a noisy tenant spikes storage, or an AI feature suddenly drives token costs up, teams need that signal now, not after the month closes. Attribute’s runtime model gives engineering teams near real-time cost monitoring based on live system behavior, so overspend gets caught before it compounds.
AI and LLM cost attribution
AI costs are a real COGS issue. Token usage varies widely by customer, workflow, and feature, and doesn’t fit neatly into existing pricing models.
Attribute tracks LLM token costs by customer, feature, and team, helping companies understand where AI spend creates value and where it erodes margin. That supports better pricing design, feature controls, and product investment decisions. For teams building AI products, this is no longer a roadmap item. It’s a current requirement.
Cloud cost coverage across AWS, Snowflake, MongoDB Atlas, and OpenAI
Modern cost-to-serve analysis can’t stop at AWS. SaaS companies carry meaningful spend in Snowflake, MongoDB Atlas, Datadog, and OpenAI alongside core Kubernetes infrastructure. Attribute connects those costs back to customers, features, and internal owners, not just vendor line items.
What to look for in a FinOps tool for Kubernetes and SaaS
The right evaluation question isn’t “how good is the dashboard?” It’s “can this tool actually see my cost drivers?”
Ask:
- Does it work without reliable tagging?
- Can it allocate shared costs based on actual usage?
- Does it support customer and tenant-level attribution?
- Can it see self-managed infrastructure like Kafka and Elasticsearch?
- Does it provide near real-time visibility?
- Can it attribute AI and LLM costs?
Most tools can report spend. Fewer can explain it. Very few can explain it at the level needed for multi-tenant SaaS unit economics.
Why Attribute
Attribute is built for SaaS companies that have outgrown billing-based FinOps. It’s designed for teams running Kubernetes, shared services, and external platforms where tags are incomplete and customer profitability matters.
Core capabilities:
- FinOps without tagging via eBPF-based runtime observability
- Automatic workload discovery and dependency mapping
- Shared cost allocation based on actual runtime behavior
- Near real-time Kubernetes cost monitoring
- Customer-level profitability and cost-to-serve analysis
- Visibility into self-managed Kafka, Elasticsearch, and RabbitMQ on EC2
- AI and LLM cost attribution by customer, feature, or team
- Deployment via CloudFormation or Terraform with no code changes
Customers include Monday.com, Skechers, Riskified, Salt Security, and Island. More at attrb.io/customers.
Who should consider Attribute
Strong fit for SaaS companies with:
- Kubernetes or EKS-heavy infrastructure
- Multi-tenant architectures
- Cloud spend above roughly $3M
- Weak or inconsistent tagging
- Large shared cost buckets
- Self-managed infrastructure on EC2
- Significant spend in Snowflake, MongoDB Atlas, or OpenAI
- A need to measure gross margin by customer or feature
Every other tool reads the same billing data that’s been available for 15 years. Attribute reads the live system. That’s the difference.